
NLP Pipelines
Enterprises can use the services of Webex Bot Builder intelligence rather than building a complete chatbot. An NLP pipeline bot is built using intelligence modules and is exposed as a service.
Webex Bot Builder platform enables developers to leverage pre-built Intelligence Modules (third-party or Webex Bot Builder libraries). These libraries help to "understand" the user's natural language input. A developer can choose the libraries they wish to include and also determine the order in which they are invoked. This selection, arrangement, and configuring of Intelligence Modules can be done through the Pipeline tab. Whenever an input is received from a user, it is parsed and passed through this pipeline. All the modules in the pipeline execute on this input text in sequential order.
For example, performing a spell check, date and time recognition from an application form, or converting audio into text.
Building an NLP pipeline bot
Follow these steps to build an NLP pipeline based bot (Bot intelligence as a service):
- Click +New NLP Pipeline.

New NLP Pipeline bot
The Bot Profile screen appears.

- Specify this information and click Done to create a new pipeline bot.
| Field | Description |
|---|---|
| Bot Unique Name | A unique name for the bot that appears in the Bot URL that is used to chat with the Bot. The name cannot be edited once the bot is created. This appears below the heading and is used to define the purpose or scope of the bot. |
| Bot Name | Display name for the bot. When the bot is accessed, the name of the bot will be displayed in the bot chat window beside the bot logo. |
| URL for the Bot Logo/Brand Image | The URL from where the bot logo or image defaults. |
- After the bot creation, from the categorized Intelligence libraries based on the media type on the NLP tab of the Input Recognition screen, click add to add the module to the Bot Intelligence Pipeline on the left-hand side. These modules are invoked in the order they are arranged.
Note: Modules related to text, image, video, and audio are grouped on each tab. Bot developers can now quickly access the text modules, image modules, video modules, and audio modules by navigating to the Text, Image, Video, and Audio tabs separately.
For more information, see the Intelligence module.

Modules to add in the pipeline
Note: You can remove the modules that are added to the bot intelligence pipeline, using the remove icon corresponding to the module.

- To reorder the modules manually, drag the module and drop it at the required place.
- Click Update Pipeline.
When the bot building is successful, the bot is displayed on the NLP Pipelines tab of the Dashboard.
NLP pipeline testing
Pipeline bot testing can be performed either by providing the text or URL on the Test pipeline bot screen. Based on the bot intelligence modules configured in the NLP, consumer inputs are processed through this sequence of modules to segregate the input parameters accordingly for analyzing the sentiment of the text, performing the spell check, expanding the contracted consumer text, and so on.
Follow these steps to test a pipeline based bot:
- Select a specific pipeline bot on the NLP pipelines tab of the dashboard.
- Click the Test tab. The Test NLP pipeline screen appears.

Pipeline bot screen for testing
- Select the Message type input. Possible values:
- Text
- URL

Message type inputs
- Enter the message in the provided Message box, in case if you set the Message type input to Text
Note: Provide the URL, if you set the Message type Input to URL. You also have to add URL-related modules in the bot intelligence pipeline (such as OCR). - Click Test pipeline to classify the input parameters in the consumer message based on the configured bot intelligence modules.

Test result of pipeline bot for the text message input

Test result of pipeline bot for the URL input

Test result of pipeline bot for URL input configured with image captioning module
Testing in other apps
Getting bot access token
To integrate the bot with other systems, an access code is required. Follow these steps to get the access code of the bot:
- Navigate to the NLP pipelines tab on the dashboard.

- Click the required bot.
- Click the ellipses icon corresponding to a specific bot and click Copy Access Token.

Testing in Postman
Follow these steps to access your pipeline bot and test it through postman.
- Open a new postman tab by clicking on + set request type as 'Post' from the dropdown

- Enter the request URL: https://imibot.ai/api/v1/webhook/intelligent/
- Select the Headers section to provide these values:
| Key | Value |
|---|---|
| bot-access-token | <Your bot's access token copied from Webex Bot Builder> |
| Content-Type | application/json |
- Navigate to Body section, select type as ‘raw’, and enter your request in this format:
{
"msg": "your test text goes here",
"msg_type": "text"}
Transaction history in NLP pipelines
NLP pipelines contain a ‘Transactions’ tab similar to ‘Sessions’ in Q&A and Task bots. This allows developers to track usage of their pipelines and view the results of individual NLP transactions, providing granular insights into the performance of individual modules for each transaction. NLP node in Webex connect is powered by a system created NLP pipeline in each tenant. With the addition of this feature, developers stand to gain a better understanding of their conversational automation performance and can adjust their flows accordingly.
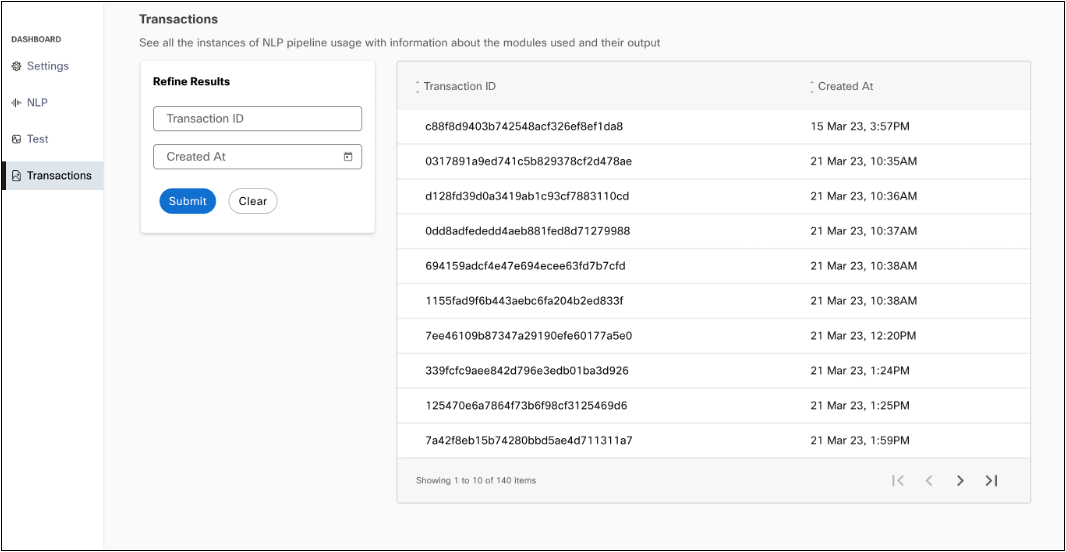
Transactions tab in NLP pipelines
Users can search for transactions they’re interested in using a transaction ID or the date range when the transaction took place.
Clicking on any transaction in the table will display transaction details. User message along with information about all the modules used with their outputs is available on the left. The right side contains the raw response of the NLP pipeline.
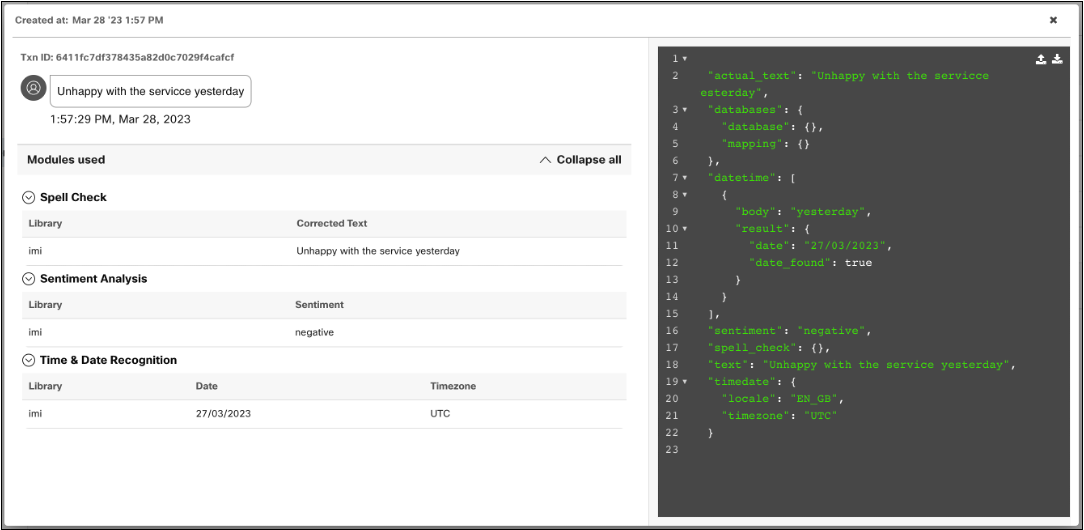
Transaction details with modules and their output on the left and raw response on the right
Intelligence modules
Intelligence modules are pre-built libraries available to the developers. These include various third-party libraries as well as libraries built by Webex Bot Builder and can be leveraged by developers while designing and building their bot. These modules can be used by including them in the Pipeline.
The following table contains the list of all available intelligence modules, a brief explanation of their purpose, and details on different implementations available on IMIbot.ai. Scroll right for columns that aren't visible.
| Function | Details | IP Owner | Description | Pros | Cons | Sample Input | Sample Output |
|---|---|---|---|---|---|---|---|
| Spell Check | Checks for misspelt words in a given sentence and sends the sentence back with those words corrected to the most likely words. | IMImobile | This implementation is based on an open-source project which takes a deterministic approach and is non-contextual in nature. | cheaper, no external call, slightly faster | not contextual, slightly lower accuracy | Spell check module | spell cheek module |
| Microsoft | This is a Microsoft service and involves an external API call. It is machine learning based and is contextual. | contextual, slightly higher accuracy, improves over time | relatively more expensive, involves an external call, slightly slower | spel chek module | spell check module | ||
| Units Recognition | Parses a given sentence for a mention of one or more of the following metrics and the corresponding unit of measurement used. | IMImobile | Metrics currently supported: Distance Volume Currency | GBP 50 | "units": [ { "result": "50 GBP", "unit": “GBP", "unittype": "amount-of-money", "value": 50 } | ||
| Numbers Recognition | Parses a given sentence for a mention of a number or a numeric quantity and extracts it in the response. | IMImobile | Recognizes numbers in both numeral as well as word forms | five million | { "numbers": [ 5000000 ] } | ||
| Date & Time Recognition | Parses a given sentence for a mention of a date or time and extracts them into the most likely standard representations. | IMImobile | Recognizes time and dates in both structured as well as natural language forms | 5 days after day after tomorrow at 9AM | { "date": "21/08/2018", "time": "09:00" } | ||
| Word Tokenization | Tokenization Parses a given sentence into an array of individual words (tokens). | IMImobile (Spacy) | This implementation is based on a fast, free and open-source library called Spacy | no external calls, faster | comparatively lesser flexibility, opinionated, only supports English | Elon Musk is the CEO of Tesla. He is also the CEO of SpaceX. | { "word_tokens": [ "Elon", "Musk", "is", “still", “the", "CEO", "of", “Telsa" ] } |
| The capital of Canada is Ottawa. I am going to travel to Ottawa | "word_tokens": [ "The", "capital", "of", "Canada", "is", "Ottawa", ".", "I", "am", "going", "to", "travel", "to", "Ottawa" ] | ||||||
| IMImobile (NLTK) | Based on a suite of libraries and programs for symbolic and statistical NLP for English | greater flexibility, no external calls, supports multiple languages | lower performance | ||||
| Sentence Tokenization | Tokenization Parses a given paragraph into an array of sentences. | IMImobile (Spacy) | This implementation is based on a fast, free and open-source library called Spacy | no external calls, faster | comparatively lesser flexibility, opinionated, only supports English | Elon Musk is the CEO of Tesla. He is also the CEO of SpaceX. | { "sentence_tokens": [ "Elon Musk is the CEO of Tesla.", "He is also the CEO of SpaceX." ] } |
| IMImobile (NLTK) | Based on a suite of libraries and programs for symbolic and statistical NLP for English | greater flexibility, no external calls, supports multiple languages | lower performance | ||||
| Lemmatization | Parses a given sentence and returns the root forms (aka lemmas or lexemes) of all the words in the sentence. | IMImobile (Spacy) | This implementation is based on a fast, free and open-source library called Spacy | no external calls, faster | comparatively lesser flexibility, opinionated, only supports English | I am loving it | I be love -PRON- |
| A paid service by Google | contextual, slightly higher accuracy | not free, involves an external call, slightly slower | I am loving it | I be love it | |||
| Parts-Of- Speech Tagging | Parses a given sentence and assigns the most appropriate part-of- speech tag to each of the words in the sentence. | IMImobile (Spacy) | This implementation is based on a fast, free and open-source library called Spacy | no external calls, faster | comparatively lesser flexibility, opinionated, only supports | Bots are awesome | {"pos_tag": "NOUN", "word": "Bots"}, {"pos_tag": "VERB", "word": "are"}, |
| English | {"pos_tag": "ADJECTIVE", "word": "awesome" } | ||||||
| A paid service by Google | contextual, slightly higher accuracy | not free, involves an external call, slightly slower | Bots are awesome | {"person": "PERSON_UNKNO WN", "pos_tag": "NOUN", "proper": "PROPER_UNKNO WN", "word": "Bots"}, {"person": "PERSON_UNKNO WN", "pos_tag": "VERB", "proper": "PROPER_UNKNO WN", "word": "are" }, {"person": "PERSON_UNKNO WN", "pos_tag": "ADJECTIVE", "proper": "PROPER_UNKNO WN", "word": "awesome" } | |||
| Sentiment Analysis | Analyzes a given sentence or phrase for the sentiment expressed in it as one of three | IMImobile (Vader) | This implementation is based on a free and open-source library called VADER | cheaper, no external call, slightly faster | lower accuracy | this is awesome | positive |
| possibilities: negative, neutral and positive. | I am unhappy with the service | { "inputParams": { "actual_text": "I am unhappy with the service", "bot_id": "502", "databases": { "database": {}, "mapping": {} }, "sentiment": "negative", "text": "I am unhappy with the service" } | |||||
| A paid service by Google | higher accuracy | not free, involves an external call, slightly slower | you are splendidly stupid | negative | |||
| Named Entity Recognition | Extracts named entities from the input text. Commonly supported entities are nationalities, location, buildings, people, events, organizations, etc. | IMImobile (Spacy) | This implementation is based on a fast, free and open-source library called Spacy | no external calls, faster | lower entity coverage, lower accuracy | IMImobile is listed in London | { "gpe": ["London”] } |
| Dandelion | A paid service by Dandelion | higher accuracy, higher entity coverage, improves over time | not free, involves an external call, slightly slower | IMImobile is listed in London | { "gpe": ["London"], "org": ["IMImobile"], "person": [] } | ||
| Question Detection | Determines whether the input phrase is a question. | IMImobile | A module built in-house based on other NLP building blocks | How much did they pay for it? | pay for it? { "accomp": “much”, "method": “auxpass starting with WH”, "questype": “how” } | ||
| Language Translation | Translates text from a source language to the target language. | A paid service by Google | very accurate, great language support | expensive, involves an external call | Hello | Bonjour | |
| Profanity filter | Parses a given input against a pre-configured list of profane words and masks them out | IMImobile | Custom implementation based on other NLP building blocks | What the fuck | What the f**k | ||
| Chunking | Retrieves phrases from input text | IMImobile (Spacy) | This implementation is based | the autobiography of John has 13 chapters | "chunking": [ "the autobiography", "John", "13 chapters" ] | ||
| on a fast, free and open-source library called Spacy | |||||||
| Common sense | Detects if the input phrase falls under any of a large category set of small talk or common sense intents like greetings, abuse, and so on. | IMImobile | Custom implementation based on other NLP building blocks | hi | "intent": "isGreeting" | ||
| Contraction | Expands contracted text | IMImobile | Custom implementation based on other NLP building blocks | I didn't receive the credit card yet | "expanded_text": "I did not receive the credit card yet" | ||
| Custom Named Entity Recognition | Picks and classifies entities from input text to predefined, custom entity classes. | IMImobile | Custom implementation based on other NLP building blocks | IMImobile is listed in London | “city”:”London” | ||
| Emotion Classifier | Detects emotions in a given text | IMImobile | Custom implementation based on other NLP building blocks | I am unhappy with your service | "emotionclassifier": {}, "emotions": [ { "angry": 44, "disapproval": 5, "irritation/skepticism": 5 } | ||
| Image captioning | Captions a given image | Azure | A paid service by Microsoft Azure | https://iso.500px.com/wp-content/uploads/2015/03/business_cover.jpeg | { "confidence": 0.9841809900994755, "text": "a man wearing glasses and a suit and tie" } ], "tags": [ "person", "wearing", "necktie", "man", "suit", "clothing", "jacket", "glasses", "looking", "bow", "gray", "brown", "dressed", "young", "hat", "standing" ] | ||
| Language Detection | Detects the language of given text | A paid service by Google | Book doctor's appointment هاو آري أنت | "language": "en", "language_detection": {}, "text": "Book doctor's appointment " "language": "ar", "language_detection": {}, "text": "هاو آري أنت" | |||
| Numeric Range Detector | Detects numeric range/interval for 2 languages - English, Hindi | IMImobile (haptik) | This implementation is based on a fast, free and open-source library called haptik | You can refer from 7-18 pages for information related to NLP module. | "number_ranges": [ { "max": "18", "min": "7", "original_text": "7-18" } | ||
| OCR | Takes an image url as an input and returns the text detected in the image as response. | A paid service by Google | https://preview.redd.it/pvqsd1lov7m71.jpg?width=509&auto=webp&s=02d4b24842c0f07564e7a17a74f691333190e7ff | { "bounds": "(93,151),(451,151),(451,719),(93,719)", "description": "THE CHOICE IS YOURS\nII I-\nH E\nMATRI X\nRESURRECTIONS\nDECEMBER\nONLY IN CINEMAS\nwhatisthematrix.c om\n" } | |||
| Parse tree generation | Generates a grammatical dependency graph or parse tree of a given sentence using the standard spacy vocabulary nomenclature. | A paid service by Google | Book an appointment | { "inputParams": { "actual_text": "Book an appointment", "bot_id": "502", "databases": { "database": {}, "mapping": {} }, "parsetree": [ { "outward_tokens": [ { "index": 2, "word": "appointment" } ], "parse_label": "ROOT", "pos": "VERB", "token": { "index": 0, "word": "Book" }, "towards_token": {} }, { "outward_tokens": [], "parse_label": "DET", "pos": "DETERMINER", "token": { "index": 1, "word": "an" }, "towards_token": { "index": 2, "word": "appointment" } }, { "outward_tokens": [ { "index": 1, "word": "an" } ], "parse_label": "DOBJ", "pos": "NOUN", "token": { "index": 2, "word": "appointment" }, "towards_token": { "index": 0, "word": "Book" } } ], "text": "Book an appointment" } | |||
| IMImobile (Spacy) | This implementation is based on a fast, free and open-source library called Spacy | Order two large sausage pizza | { "inputParams": { "actual_text": "Order two large sausage pizza", "bot_id": "502", "databases": { "database": {}, "mapping": {} }, "parsetree": [ { "outward_tokens": [ { "index": 1, "word": "two" }, { "index": 4, "word": "pizza" } ], "parse_label": "ROOT", "pos": "NOUN", "token": { "index": 0, "word": "Order" }, "towards_token": {} }, { "outward_tokens": [], "parse_label": "NUMMOD", "pos": "CARDINAL", "token": { "index": 1, "word": "two" }, "towards_token": { "index": 0, "word": "Order" } }, { "outward_tokens": [], "parse_label": "AMOD", "pos": "ADJECTIVE", "token": { "index": 2, "word": "large" }, "towards_token": { "index": 4, "word": "pizza" } }, { "outward_tokens": [], "parse_label": "COMPOUND", "pos": "NOUN", "token": { "index": 3, "word": "sausage" }, "towards_token": { "index": 4, "word": "pizza" } }, { "outward_tokens": [ { "index": 2, "word": "large" }, { "index": 3, "word": "sausage" } ], "parse_label": "DOBJ", "pos": "NOUN", "token": { "index": 4, "word": "pizza" }, "towards_token": { "index": 0, "word": "Order" } } ], "text": "Order two large sausage pizza" }, "pipelines": [ { "_id": "5b8901000e0ff44f7e071e41", "cons": "comparatively lesser flexibility, opinionated, platform only supports English", "contextual": false, "created_at": 1535705344000, "default": false, "description": "", "display_values": {}, "id": 14, "input_params": {}, "is_added": true, "is_paid": "free", "library": "spacy", "module": "parsetree", "pipeLineSrc": "assets/img/pipeline-no-hover-drag.svg", "pros": "free, no external calls, faster", "unique_name": "Spacy Parse Tree", "updated_at": 1535705344000 } ], "timeStamp": "2021-09-13 06:32:10.187997", "timestamp": "Mon, 13 Sep 2021 12:02:10 GMT", "transaction_id": "d4c6f3fea251456096a481c3170845a8" } | ||||
| Phone number detection | Detects phone numbers for 6 languages - english, hindi, gujarati, marathi, tamil and bengali | IMImobile (haptik) | This implementation is based on a fast, free and open-source library called haptik | If you require any further information, feel free to contact us at @ 91234****2. | "phone_numbers": [ { "original_text": "9123457687", "phone_number": "9123457687" } | ||
| Text to speech | Converts the given text into speech file. | A paid service by Google | |||||
| Azure | A paid service by Microsoft Azure | My Credit Card is lost or stolen, what do I need to do? | { "inputParams": { "actual_text": "My Credit Card is lost or stolen, what do I need to do?", "audio_url": "http://imibot-production.s3.amazonaws.com/6/502/502/audio/8968.mp3", "bot_id": "502", "databases": { "database": {}, "mapping": {} } | ||||
| Amazon | A paid service by Amazon |
Updated 6 months ago